大数据技术之高频面试题 数据处理技术的技术开发深度解析
在当今数据驱动的时代,大数据技术已成为企业核心竞争力之一。在招聘大数据技术开发岗位时,数据处理技术是面试官考察的核心领域。本文将深入解析数据处理技术开发相关的高频面试题,旨在帮助求职者系统梳理知识体系,掌握核心要点。
一、 数据处理流程核心概念
- 数据采集与接入
- 高频问题:请简述Flume、Kafka、Sqoop等数据采集工具的原理、适用场景及区别。
- 技术要点:
- Flume:基于流式架构的日志采集、聚合和传输系统,核心概念包括Agent、Source、Channel、Sink。面试常考其可靠性保证(如Channel的事务机制)和负载均衡策略。
- Kafka:分布式消息队列,用于构建实时数据管道和流式应用。重点理解其高吞吐原理(顺序IO、零拷贝)、Topic、Partition、副本机制、生产者/消费者API以及如何保证消息不丢失、不重复。
- Sqoop:用于Hadoop与关系型数据库间数据迁移的工具。需掌握其导入导出原理(MapReduce实现)、增量导入方式及性能优化。
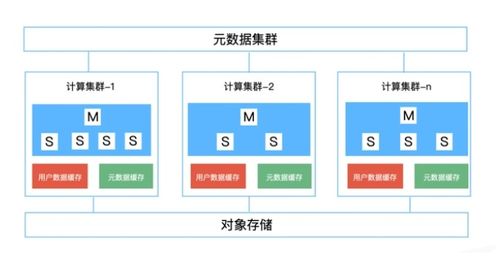
- 数据存储
- 高频问题:HDFS的读写流程是怎样的?HBase的存储模型与HDFS的关系是什么?
- 技术要点:
- HDFS读写流程:需清晰描述客户端与NameNode、DataNode的交互细节,包括块的概念、机架感知、副本放置策略。
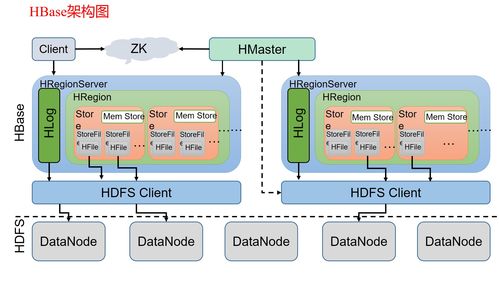
- HBase:理解其基于HDFS的LSM树存储结构,RowKey设计原则(避免热点问题),Region分裂机制,以及如何与MapReduce/Spark集成进行批量数据处理。
二、 批处理与流处理框架
- 批处理:MapReduce与Spark Core
- 高频问题:Spark为什么比MapReduce快?简述Shuffle过程及其优化。
- 技术要点:
- Spark优势:基于内存计算的DAG执行引擎,减少了磁盘I/O;多阶段任务并行,避免了MapReduce重复的序列化与落盘。
- Shuffle:是连接Stage的关键环节,是性能瓶颈。需详细说明Map端和Reduce端的流程(Combine、Partition、Sort、Spill、Merge)。优化手段包括调整缓冲区、使用ByPass机制、选择高效的序列化方式(如Kryo)、合理设置分区数。
- 流处理:Spark Streaming与Flink
- 高频问题:对比Spark Streaming的微批处理与Flink的真正的流处理。什么是CEP?如何实现Exactly-Once语义?
- 技术要点:
- 架构对比:Spark Streaming将流离散化为一系列小批量(DStream),本质是批处理;Flink将批视为有界的流,采用事件驱动的流式架构,延迟更低。
- CEP(复杂事件处理):用于在数据流中检测特定事件模式。需了解其基本概念和应用场景(如金融风控、物联网监控)。
- Exactly-Once语义:是流处理的核心保证。需理解Spark基于WAL和幂等输出的实现,以及Flink基于分布式快照(Checkpoint)和两阶段提交(2PC)的实现原理。
三、 数据处理开发实战
- 数据清洗与质量保证
- 高频问题:如何处理数据中的脏数据(缺失、异常、重复)?如何设计数据质量监控体系?
- 技术要点:
- 清洗策略:根据业务规则进行填充(均值、中位数)、过滤、去重。常用Spark SQL、DataFrame API或UDF实现。
- 质量监控:定义完整性、准确性、一致性、及时性等维度指标,通过定时任务进行校验和告警。
- 性能调优
- 高频问题:遇到一个运行缓慢的Spark/MapReduce作业,你会如何着手排查和优化?
- 技术要点:
- 排查步骤:查看作业执行计划(如Spark的
explain)、监控GC情况、分析数据倾斜(通过Key的分布)。
- 优化手段:
- 资源层面:调整Executor数量、核心数、内存分配(堆内/堆外)。
- 任务层面:使用广播变量减少数据传输;对RDD进行持久化(选择正确的StorageLevel);合理设置并行度。
- 数据倾斜处理:使用加盐(Salt)或两阶段聚合;将倾斜Key过滤出来单独处理;使用Flink的
rebalance等操作符。
- SQL与编程API
- 高频问题:Hive SQL优化有哪些常见手段?Spark SQL中DataFrame、DataSet、RDD的区别与联系?
- 技术要点:
- Hive SQL优化:使用分区和分桶;选择适当的文件格式(ORC, Parquet)和压缩格式;避免笛卡尔积;使用MapJoin处理小表关联;调整并行度等。
- Spark SQL三剑客:理解RDD(弹性分布式数据集,底层API)、DataFrame(以命名列组织的分布式数据集,等价于RDD[Row])、DataSet(强类型API,结合了RDD和DataFrame的优点)的演进和适用场景。
四、 新兴趋势与架构设计
- Lambda与Kappa架构
- 高频问题:请描述Lambda架构的组成和优缺点。为什么Kappa架构越来越受关注?
- 技术要点:
- Lambda架构:包含批处理层(处理历史全量数据,保证准确性)、速度层(处理实时增量数据,保证低延迟)和服务层(合并视图)。优点是兼顾准确与实时,缺点是维护两套系统复杂性高。
- Kappa架构:统一使用流处理系统,通过重放历史数据来满足批处理需求。得益于Flink等流处理引擎的成熟,架构更简洁,但对消息队列的存储能力和流处理引擎的回溯能力要求高。
- 数据湖与湖仓一体
- 高频问题:数据湖、数据仓库和数据湖仓的区别是什么?
- 技术要点:理解数据湖(存储原始格式数据,支持灵活分析)、数据仓库(存储清洗后的结构化数据,服务于BI)的概念,以及湖仓一体(在数据湖上构建数据仓库的管理和性能特性)的融合趋势及其技术实现(如Delta Lake, Apache Iceberg)。
###
面试中对数据处理技术的考察,不仅限于对工具和概念的背诵,更注重对原理的深刻理解、对技术选型的思考以及在真实场景中解决问题的能力。开发者应深入理解数据在系统中的完整生命周期,从采集、存储、计算到应用,并结合具体业务需求,构建高效、稳定、可扩展的数据处理管道。持续关注流批一体、实时数仓等前沿方向,将使你在技术浪潮中保持竞争力。
如若转载,请注明出处:http://www.yingling8888.com/product/75.html
更新时间:2026-07-29 13:47:00