大数据技术原理与应用 第九章 数据处理技术的核心开发实践
随着大数据技术体系的不断演进,数据处理技术作为从原始数据中提取价值的关键环节,其开发实践日益受到关注。本章聚焦于大数据处理技术的核心开发原理与应用,旨在为技术开发者提供一套从理论到实践的清晰路径。
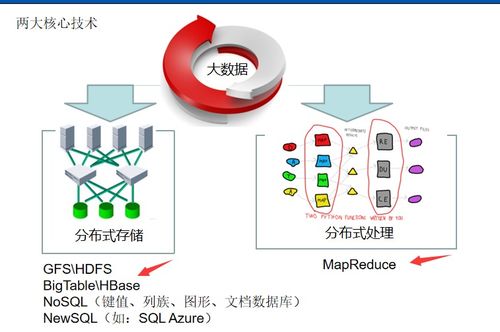
数据处理技术开发的核心在于构建高效、可靠且可扩展的数据处理流水线。这通常涵盖数据采集、存储、计算、分析与服务等多个层面。在技术选型上,开发者需要根据业务场景的具体需求,在批处理与流处理之间做出权衡。例如,对于需要高吞吐、离线分析的历史数据,Apache Hadoop的MapReduce或Apache Spark的批处理引擎是经典选择;而对于要求低延迟、实时响应的场景,Apache Flink、Apache Storm或Spark Streaming等流处理框架则更为合适。
在开发实践中,有几个关键技术点需要重点关注:
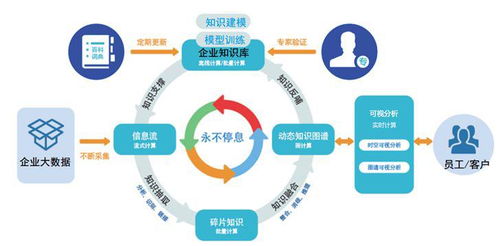
数据质量与一致性是基石。开发中必须设计有效的数据清洗、去重、校验与修复机制。利用如Apache NiFi、Kafka Connect等工具可以实现可靠的数据摄取,并结合Schema Registry管理数据格式,从源头保障质量。
计算模型的抽象与优化至关重要。无论是MapReduce的“分而治之”,还是Spark基于内存的DAG(有向无环图)执行模型,理解其底层原理有助于编写更高效的代码。开发者应熟练运用分区(Partitioning)、广播变量(Broadcasting)、缓存(Caching)等技术来优化性能,并关注数据倾斜等常见问题的解决方案。
状态管理与容错性是流处理开发中的难点与重点。像Flink提供的精确一次(Exactly-once)语义状态管理,允许开发者在应用故障时恢复状态,确保计算结果的准确性。这要求开发者在设计应用时,明确状态后端的选择和检查点(Checkpoint)机制的配置。
与存储系统的深度集成是提升效率的关键。数据处理框架需要与HDFS、HBase、Kafka、各类云存储及数据湖(如Delta Lake、Iceberg)无缝协作。开发者应理解不同存储系统的特性(如列存、索引、事务支持),以便在读写数据时做出最佳设计。
可观测性与运维是生产级开发不可忽视的一环。集成监控指标(如吞吐量、延迟)、日志聚合与告警系统,并利用Kubernetes等平台实现容器化部署与弹性伸缩,能极大地提升系统的可维护性。
数据处理技术开发正朝着更智能化、一体化和云原生的方向发展。机器学习与数据处理的融合(如Spark MLlib)、流批一体架构的普及(如Flink的统一API),以及Serverless数据处理服务的兴起,都在不断降低开发门槛并提升效率。开发者需持续学习,掌握核心原理,并灵活运用工具,方能构建出稳健而强大的大数据处理系统,真正释放海量数据的潜在价值。
如若转载,请注明出处:http://www.yingling8888.com/product/78.html
更新时间:2026-06-19 12:25:15